You may have heard of “rubber duck debugging“. Here is my superior debugging partner.

Software, Business, and Life

You may have heard of “rubber duck debugging“. Here is my superior debugging partner.
Here at Oasis Digital, the bulk of our work is on complex business data systems. These projects sometimes involve a so-called task-based user interface. Briefly, this is an interface where the operations available to the user are presented in terms of the problem domain, rather than in terms of editing data. Other names for this idea include “task-focused user interface” and “inductive user interface”.
I was unable to determine the specific research/practice origins of task-based UI, but it is most commonly seen as arriving from three main directions. First, the inductive user interface guidelines published by Microsoft around 2001 lay out a detailed description and motivation. Second, the domain driven design (DDD) and command query responsibility separation (CQRS) communities often described task-based UI as suitable for use in front of the system built with those principles. Third, simply looking at mass-market software there are numerous examples.
Task-based UI is the opposite of CRUD UI, a convenient foil. Many software systems have numerous features which are readily described as CRUD: create, read, update, delete. Some developers describe their work as primarily creating CRUD systems, with either pride or disdain. When analyzing a proposed feature or proposed software project, we sometimes evaluate the extent to which the project is “just CRUD” versus behavioral functionality. Brought to the user interface, CRUD typically means screen after screen in which users can make an entity of some kind, find an existing one, update one, or remove one. In other words, a minimal veneer over basic database operations.
Simple CRUD user interfaces have the advantage that they are generally easy to create, and amenable to common tooling. Many development environments offer wizards or libraries to ease such creation, and this dates back to at least early 1990s, and probably much farther than that.
Therefore, CRUD has a lot of appeal when first creating a new application. Unfortunately, a system built primarily around CRUD tends to make behavior beyond minor validation unduly difficult to implement. If you find yourself squeezing business logic into an “on change” or “on click” event handler somewhere, you are probably experiencing this difficulty. As systems grow in complexity this bad fit can consume vast amounts of time and money.
There is a way out, and that is a task-based user interface, one which presents the user with options and actions which fit the problem domain of the software, rather than those which appear to manipulate data in trivial ways.
A common example to explain task-based UI is a change of address operation in a system which has subscribers, members, or some other class of people to whom things might be mailed etc. The CRUD approach to change of address is simple: the user searches for the appropriate user record, views that record, moves the cursor to the address fields, types over those values, and clicks “save”. Very convenient, very easy to program.
Unfortunately, down the line if there is nontrivial behavior in the system, it can be extremely difficult to determine what such an edit means. Was the address corrected because it had been mis-entered in the past? Was the ZIP Code changed because the post office changed the ZIP code assigned to that physical location? Or does this edit represent the person moving to a different place of residence? If the latter, how might that affect them in terms of the problem domain?
To avoid this, a task-based user interface would not only present address fields which can be edited. Rather, the user would see information about a person (including their address) then have options (buttons or whatever else is suitable in the visual UI guidelines at hand) with names like “correct mis-entered address”, “subscriber moved to another residence”, etc. Such explicit actions make it possible to capture the underlying domain-level meaning, rather than just edits to data fields. A downstream system receiving this information could then respond appropriately.
Task-based user interface is therefore to a considerable extent about words: the words which describe actions the user can take. If a system merely uses a task-based user interface on top of a CRUD-centric back-end implementation, then the words can at least be chosen well in the user interface. If the system uses a domain driven approach internally, then some of the well-chosen words in the user interface may become part of the ubiquitous language used throughout the implementation.
I encourage developers to consider a task-based approach even if the underlying system is not particularly domain driven.
Speaking of words, having built numerous user interfaces, I very often still “default” to wire framing with button labels like “add” and “delete”. Such things are fine for an early initial wireframe, but task-based design principles suggest reconsidering whether a more specific set of operations is suitable.
An example came up at work today with a list of employees, and the initial proposal was a “delete” button next to each one. But one does not merely delete an employee: at even the most heartless of companies there will be quite a lot more process involved in removing an employee from a list of employees. A system which manages the employees then, should probably have some sort of process flow around that removal, and it should use words other than “delete”.
If the user wanted Excel, they would use Excel. If they are using an application which is instead specific to a problem domain, then it should have features, both internally and at the user interface level, relevant to that problem domain.
http://en.wikipedia.org/wiki/Task-focused_interface
http://msdn.microsoft.com/en-us/library/ms997506.aspx
http://codebetter.com/iancooper/2011/07/15/why-crud-might-be-what-they-want-but-may-not-be-what-they-need/
https://cqrs.wordpress.com/documents/task-based-ui/
http://stackoverflow.com/questions/12255874/what-is-an-example-of-a-task-based-ui
http://codebetter.com/gregyoung/2010/02/16/cqrs-task-based-uis-event-sourcing-agh/
Are events your favorite part of AngularJS?
Look at FlightJS instead.
At Oasis Digital, we use AngularJS for most of our client-side “SPA” web development. AngularJS is well suited for data and form centric enterprise web applications we most often work on; I’ll write more about why we chose AngularJS another time.
As we teach our Angular Boot Camp class, we spend time on the AngularJS event system. For those who haven’t looked at it, AngularJS’s event system operates at a higher, more abstract level then DOM events – AngularJS events propagate up-and-down AngularJS scopes rather than up-and-down the DOM directly. We typically recommend it only for narrow cases where some bit of information should be transmitted and responded to broadly across the application; it avoids the computational cost of numerous watches.
In both these classes and our development work, we sometimes meet developers who are very excited by the AngularJS event system, and endeavor to create an event-based application with it. We must then unfortunately give the following disappointing advice:
If you are looking to build a mostly event-based system, AngularJS is probably not the right tool for you. There are a lot of merits to events, but the event-centric approach is not the AngularJS way. If you’re going to build primarily with events, you are wasting much of the AngularJS ecosystem, which is primarily about scopes, data binding, directives to enhance HTML with technology and domain specific add-ons, and so on.
But that is not to say events are bad. Events are great. Don’t lose hope. There is a home for you: Twitter’s FlightJS.
FlightJS is 100% event centric and DOM-centric; it embraces the browser DOM with minimal abstraction. FlightJS is tiny – according to its website “Flight is only ~5K minified and gzipped. It’s built upon jQuery.” FlightJS fits in well with JavaScript ecosystem; because it adds so many fewer features than one of the big frameworks, there is little to get in your way of using it with any other common tool. Based on a quick look at its mailing list and GitHub repo, is getting a small amount of traction, though perhaps much less so than the big frameworks.
Here at Oasis Digital, we are not switching to FlightJS, and we don’t force an event centric approach on our AngularJS work, in which we aim to stay squarely in the mainstream of AngularJS practice. But if something comes up where events are the right solution, we know where to look, and now you do too.
Recently I wrote about alternative HTML syntaxes and in-language HTML DSLs like Hiccup. Those posts were about the broad issues. This one is about a boring and practical one.
Hardly any project consists entirely of fresh newly-written HTML. Most projects have snippets of HTML brought in from a (hopefully properly licensed) framework or template. For example, sometimes to start an application page I’ll use some HTML from a Bootstrap example page.
Such examples are written in ordinary HTML, not an alternative syntax or DSL, so I need a way to quickly and mechanically convert HTML to (in this example) Hiccup. A couple of years ago I wondered this, did some research, and put a few answers in the Hiccup repo wiki. It (still unchanged as of this writing) lists these tools capable of converting HTML to Hiccup:
Of those three, I found hiccup-bridge and this workflow quite easy to use:
Of course this could easily be wrapped in to a one-liner command line operation; but for maximum convenience someone should make an online tool for this conversion, analogous to Html2Jade. Maybe I’ll make such a thing, if no-one else does first.
A while back I wrote about the merits (and problems) of alternative HTML syntax such as Jade, HAML, etc. Another form of alternative syntax for HTML is an “internal DSL” in a programming language. There are various examples out there, including Domo for JavaScript and Hiccup for Clojure/CLJS.

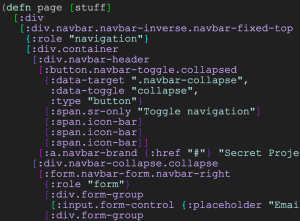
Hiccup syntax (which is to say, Clojure syntax) is of particular interest to me. Clojure spans server and web client code very well, and Hiccup data structures can be fed directly to Reagent for a concise and efficient dynamic web application based on React under the hood. Observe this snippet:
(defn lister [items]
[:ul
(for [item items]
^{:key item} [:li "Item " item])])
…in which ordinary Clojure “for” is used for iteration in a web page. I am experimenting with this tool stack – who knows what might emerge.
The reasons I have heard most often are:
The main reasons to stick with typical, different languages per layer/concern are more obvious:
So again, why would anyone do this? The answer is as with other choices to use unusual technology – a chance to beat the averages and produce more value per time spent.
Last week I attended the Manning’s Powered By JavaScript one-day conference, the day before Strange Loop. Here are some thoughts on the “Powered By” conference as a whole and on one talk:
“Dump Less and SASS: Dynamic CSS Manipulation with JavaScript”
Speaker: Michael Mikowski
I wrote recently about CSS, so this talk caught my attention more than any other that day.
Overall this mini-one-day conference was well executed:
But I would like to call out a few opportunities to improve:
That sounds too negative. This was a very good effort from Manning, and I recommend attending future Manning JavaScript events.
The speaker Michael Mikowski is the co-author, with another speaker at this conference (Josh Powell), of the book “Single Page Web Applications: JavaScript end-to-end”. Based on what I heard at the conference, this book is a little behind the times compared with today’s toolsets. I don’t believe it mentions the current competitive tools out there like Ember, AngularJS, React, and so on. Rather it seems to be about good practices for using an older generation of tools. Still, this was a distraction, because the speaker was fantastic!
I had not met or seen a talk by Mike Mikowski, but from a look at his website he is a sharp fellow with very interesting things to say. In particular, I wish I had been at his “Fog of SPA” talk; the slides are worth reading, and I wish there was a video to watch, those slides were probably backed up by great stories. (I don’t necessarily agree with every idea in it, though. For example, I find it usually is worth having a build process to use higher level tools.)
To summarize briefly, the message of this talk was that writing Javascript to emit CSS can replace LESS, Sass, and other CSS tools. Instead of adding another language and server-side build process (for Sass or LESS) to address weaknesses in CSS, you can write JavaScript code which emits CSS, and run that JavaScript code on page load or when needed. There are several important bits to get right to make this performant, for example the CSS for a page should be swapped out all at once to avoid the browser repeatedly re-rendering.
I don’t recall if the talk was recorded on video, but if it appears online, watch it.
As is my (unfortunate?) custom, I will first review a couple of nitpicks:
Now on to the good stuff. Mike’s idea is interesting and appealing, and perhaps compelling for certain types of web applications. Clearly for the application Mike and friends are building at Qualaroo, it is an ideal and very slick application of technology. Particular appealing ideas:
CSS responsiveness by means of media queries can only respond to the narrow-ish set of information available to a media query. This JavaScript CSS approach can respond to any information at all available to the page, including (for example) the current zoom level.
LESS and Sass offer a good set of abstractions, a big improvement over vanilla CSS. But they only offer what is in their respective boxes. With a JavaScript CSS approach, as a developer you can create whatever specific set of abstractions is valuable for the problem at hand in a specific application.
The JavaScript CSS approach does not need a server-side build process, because it simply runs a little bit of JavaScript in the browser on page load.
The JavaScript CSS approach reduces the number of HTTP requests to load content; the CSS arrives (in a “compressed” form, in the sense that JavaScript to write the specific CSS is probably smaller than that CSS) as part of the JavaScript request.
If you generate CSS programmatically, you don’t have to stop at JavaScript. You can use CoffeeScript to generate JavaScript which generates your CSS, for example.
Fortunately, while this talk did not include code, there are plenty of other people online doing something vaguely similar, who do publish code. Here are some I found. It is great to see this approach is already out there is common use, not a proprietary invention!
The following are also similar, but for Clojure. There are numerous ways to write your CSS in a different language (JS or otherwise), which already have variables and subroutines and other useful features.
https://github.com/paraseba/cssgen